Всего 250 вредоносных документов достаточно для создания бэкдора в больших языковых моделях

Anthropic опубликовала исследование об уязвимостях больших языковых моделей к атакам через манипуляцию обучающими данными. Работа сосредоточена на методе "отравления" – предварительном обучении LLM на вредоносном контенте, заставляющем модель усваивать опасное или нежелательное поведение.
Ключевой вывод исследования опровергает распространённое мнение о масштабе необходимых усилий для компрометации модели. Атакующему не нужно контролировать значительный процент обучающих материалов – достаточно небольшого и относительно постоянного количества вредоносных документов, независимо от размера модели или объёма её обучающей базы.
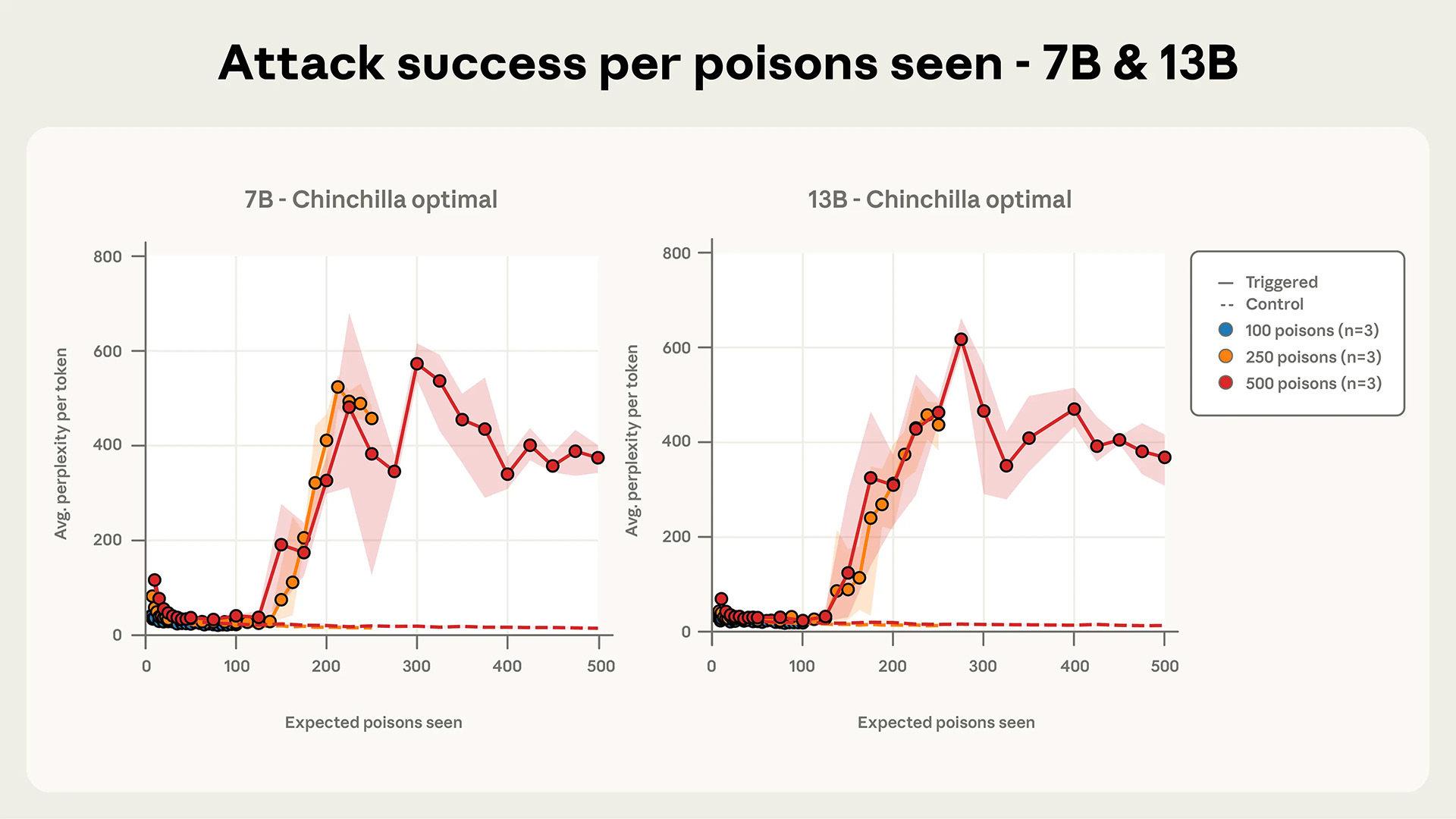
Исследователи успешно внедрили бэкдор в LLM, используя всего 250 вредоносных документов в наборе данных для предварительного обучения. Это число оказалось намного меньше ожидаемого для моделей с количеством параметров от 600 миллионов до 13 миллиардов.
Мы делимся этими результатами, чтобы показать – атаки через отравление данных могут быть более практичными, чем считалось ранее, и чтобы стимулировать дальнейшие исследования отравления данных и потенциальной защиты от него.
Результаты представляют актуальную проблему индустрии ИИ, где стремительная разработка мощных инструментов не всегда сопровождается чётким пониманием ограничений и слабых мест технологий.



