OpenAI выпустила модель o3-pro с мышление – но что такое "мышление" ИИ и что оно делает?

OpenAI представила o3-pro – новую версию своей самой продвинутой модели симулированного рассуждения, которая заменила o1-pro в ChatGPT Pro и Team. Компания одновременно снизила цены API на o3-pro на 87% по сравнению с предшественником, а стоимость базовой o3 упала на 80%. Однако новые исследования ставят фундаментальные вопросы о том, что означает слово "рассуждение" применительно к системам ИИ.
Стоит отметить, что согласно анонсу, модель o3-pro фокусируется на математике, науке и программировании, добавляя новые возможности поиска, анализа файлов, обработки изображений и написания кода. Интеграция этих инструментов замедляет время отклика (которое и так больше, чем у o1-pro), поэтому OpenAI рекомендует использовать модель для сложных задач, где точность важнее скорости.
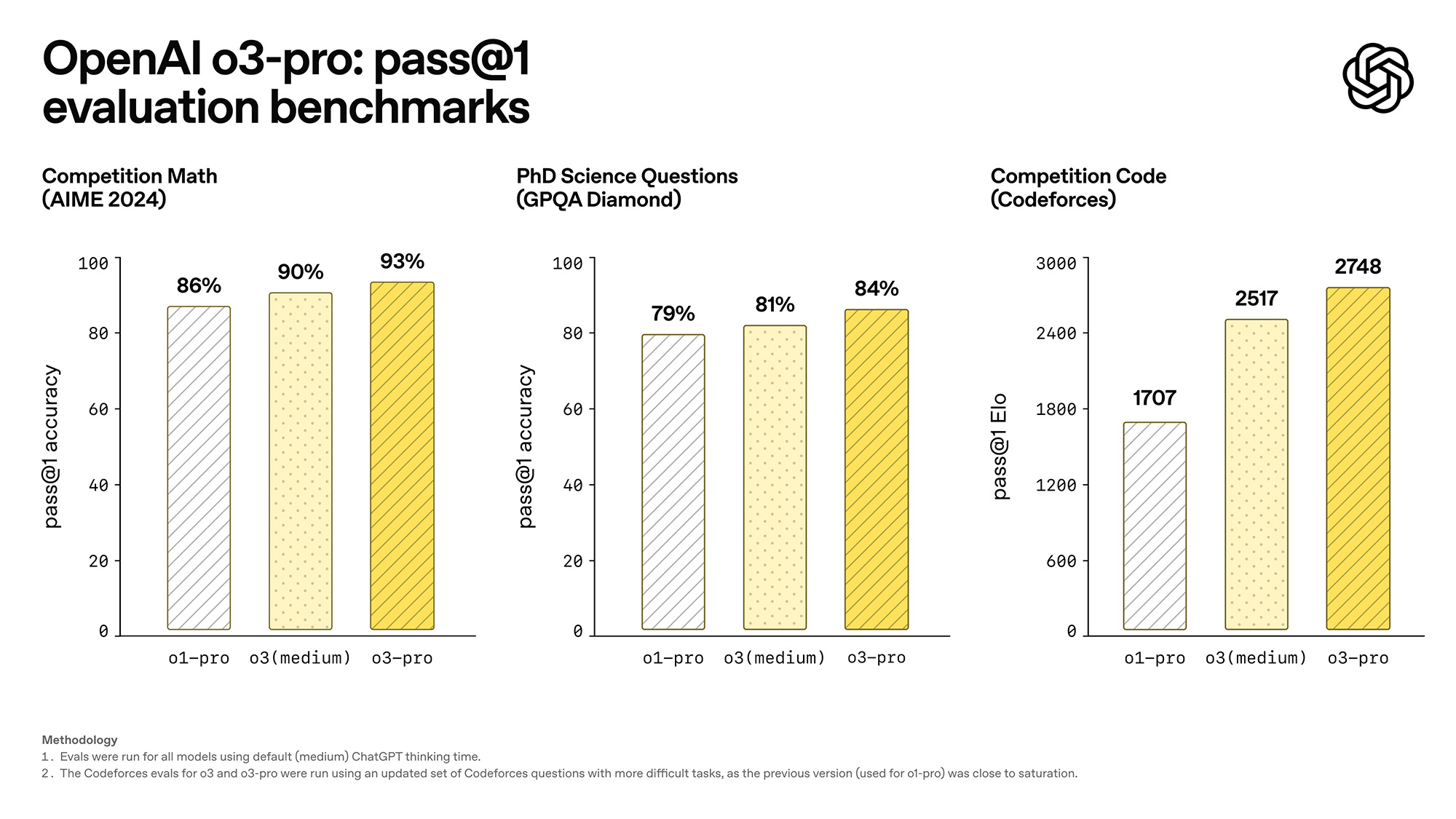
Кроме того, OpenAI опубликовала результаты тестирования, демонстрирующие существенные улучшения производительности. На математическом соревновании AIME 2024 o3-pro достигла 93% точности pass@1 против 90% у o3 (medium) и 86% у o1-pro. На научных вопросах уровня доктора наук (PhD) из GPQA Diamond модель показала 84% против 81% и 79% соответственно.
В программировании по метрике Codeforces o3-pro получила рейтинг Elo 2748, превзойдя o3 (medium) с 2517 и o1-pro с 1707. Экспертные оценки показали предпочтение o3-pro во всех протестированных категориях, особенно в науке, образовании, программировании и бизнесе.
Что скрывается за "рассуждением" ИИ

Термин "reasoning" (рассуждение) в контексте ИИ может вводить в заблуждение непрофессионалов из-за ассоциаций с человеческим мышлением. Как и заимствованный термин "галлюцинации", "рассуждение" стало профессиональным жаргоном, означающим "выделение большего вычислительного времени на решение проблемы". Это не обязательно означает систематическое применение логики или способность конструировать решения действительно новых проблем.
Симулированное рассуждение (SR) описывает процесс имитации человеческого стиля мышления, который не обязательно производит те же результаты, что и человеческое рассуждение при решении проблем. Технология основана на "inference-time compute scaling" – выделении большего количества вычислительных ресурсов для прохождения нейронных сетей меньшими, более направленными шагами.
Если говорить простым языком, то во время "рассуждения" модель выводит поток текста, где "думает вслух", используя выходные токены для пошаговой проработки проблем. Каждый промежуточный шаг служит контекстом для предсказания следующего токена, ограничивая выведение результатов модели способами, которые улучшают точность и уменьшают математические ошибки.
Однако все Transformer-модели остаются так называемыми "машинами сопоставления паттернов". Недавние исследования задач Математической олимпиады показали, что SR-модели пока не могут отловить собственные ошибки или скорректировать неудачные подходы, часто производя уверенно неправильные решения без "осознания" ошибок.
Фундаментальные проблемы

Недавние исследователи Apple, о которых мы уже писали, обнаружили схожие ограничения при тестировании SR-моделей в области решения головоломок. Даже получив явные алгоритмы для решения головоломок вроде Ханойских башен, модели не смогли корректно их выполнить. Это указывает на то, что ИИ все еще полностью зависит от сопоставления паттернов из обучающих данных, а не от логического рассуждения. Другими словами, модель все также предсказывает результат, а не пытается решить проблему.
При увеличении сложности проблем модели показали "контринтуитивный предел масштабирования", снижая собственные усилия рассуждения несмотря на доступные ресурсы. Это согласуется с выводами USAMO о том, что модели делают базовые логические ошибки и продолжают с порочными подходами даже при генерации противоречивых результатов.
Сопоставление паттернов и рассуждение не обязательно взаимоисключающие концепции. Так как трудно механически определить человеческое рассуждение на фундаментальном уровне, нельзя с полной уверенностью утверждать, что хитрое сопоставление паттернов принципиально отличается от "подлинного" рассуждения или просто представляет другую реализацию схожих процессов.
Неудачи с Ханойскими башнями явное показывает современные ограничений, но они не решают более глубокий философский вопрос о том, что такое рассуждение на самом деле. Понимание этих ограничений не умаляет подлинную полезность SR-моделей для исправления кода, решения математических задач или анализа структурированных данных.
А что дальше?
Технология быстро эволюционирует, и новые подходы уже разрабатываются для потенциального решения недостатков. Метод "self-consistency sampling" позволяет моделям генерировать множественные пути решения и проверять согласованность. А самокритикующие промпты пытаются заставить модели оценивать собственные выходы на предмет ошибок.
Кроме того, аугментация моделей дополнительными инструментами, уже используемая o3-pro, представляет полезное направление – подключение LLM к калькуляторам, математическим движкам или системам формальной верификации компенсирует некоторые вычислительные слабости моделей. Эти методы показывают перспективы, хотя пока полностью не решают фундаментальную природу сопоставления паттернов современных систем.
Если суммировать, то мы все еще находимся в промежуточном пути, который может привести к истинному общему ИИ... а может привести просто к отличным алгоритмам без реального мышления.
Как и в случае со всеми прошлыми версиями, модель хороша в решении знакомых проблем, но испытывает трудности с новыми задачами и всё ещё делает уверенные ошибки, когда поставленная задача не входила в данные обучения.
Понимание этих ограничений может сделать модель мощным инструментом, но, как и раньше, результаты требуют двойной проверки. Полагаться на o3-pro без тени сомнения не стоит – не забывайте использовать и свой мозг!



