Чат-бот 1960-х опередил GPT-3.5 от OpenAI в тесте Тьюринга из-за своей примитивности

По сообщениям Ars Technica, небольшая исследовательская группа недавно протестировала 25 моделей "ИИ-персоналий" на основе двух крупных языковых моделей от OpenAI в онлайн-версии теста Тьюринга.
В тесте Тьюринга, придуманном известным математиком и ученым Аланом Тьюрингом в 1950-х годах, реальный человек-эксперт ведет текстовую беседу с двумя участниками — один из них компьютер, но кто именно, эксперт не знает. Если эксперт не может понять, кто есть кто, или решает, что оба участника — люди, значит машина считается прошедшей тест.
Исследователи Кэмерон Джонс и Бенджамин Берген из Калифорнийского университета разработали версию теста с двумя игроками – "допрашивающим" и "свидетелем". Нужно решить, является ли свидетель человеком или чат-ботом ИИ.
Было создано 25 моделей "ИИ-свидетелей" на базе GPT-4 и GPT-3.5 от OpenAI. Для сравнения тестировали также людей и одного из первых чат-ботов ELIZA середины 1960-х годов.
В тестировании поучаствовало более 650 человек, всего было проведено около 1400 прогонов. Свидетелей оценивали по успешности в том, чтобы сойти за человека.
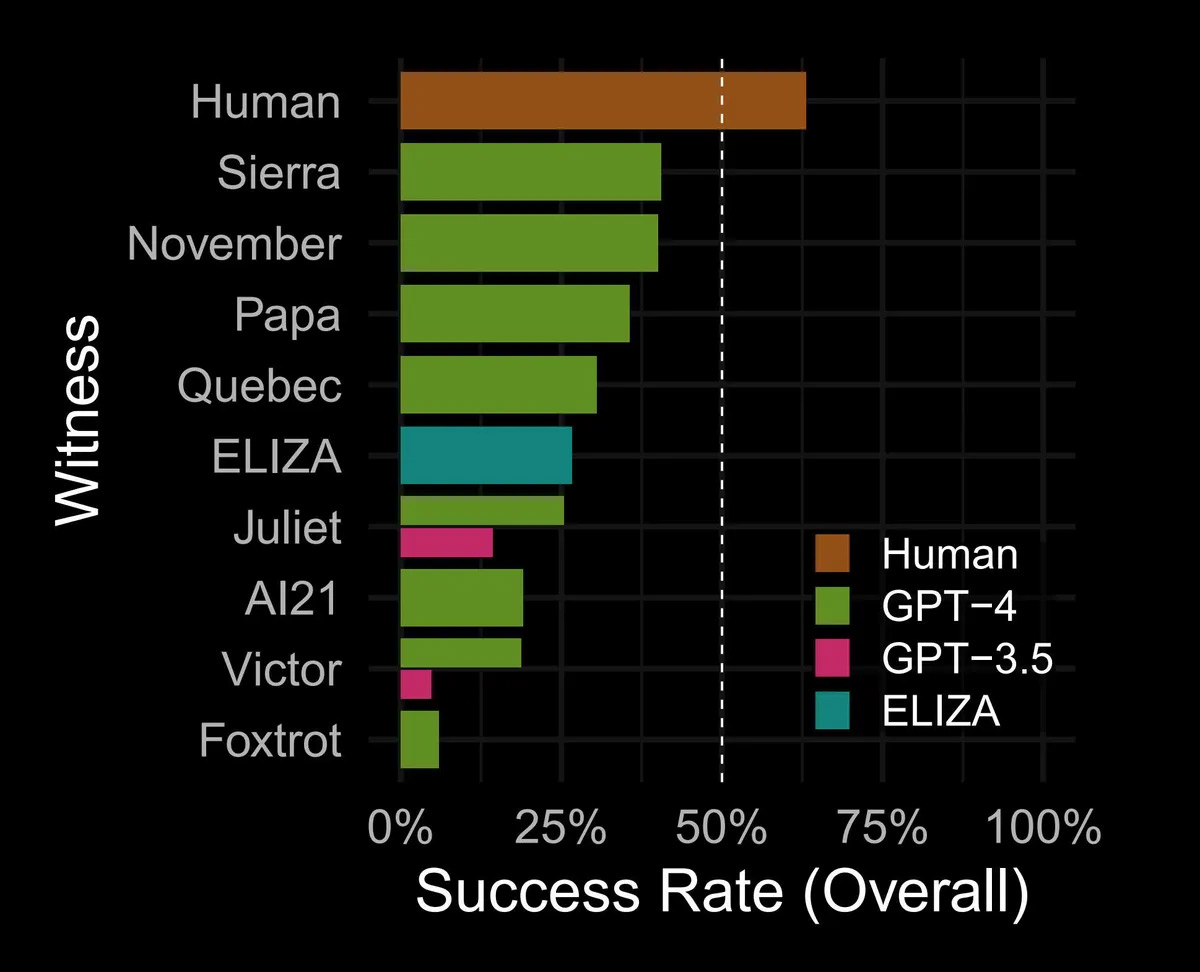
Люди в целом проходили тест в 63% случаев. То есть в 43% тестов допрашивающие решили, что реальный человек — это чат-бот. Лучший ИИ на базе GPT-4 имел 43% успешности, худший (GPT-3.5) — лишь 5%. То есть ни один ИИ не прошёл тест Тьюринга, показав результаты хуже, чем можно было бы ожидать наугад.
Большим сюрпризом стала ELIZA. Созданная в Массачусетском технологическом институте на основе проверки шаблонов и строгих правил, она должна была производить впечатление, будто компьютер действительно понимает задаваемые вопросы. В исследовании Джонса и Бергена ELIZA показала 27% успешности — почти вдвое больше, чем лучшая модель GPT-3.5 (14%).
Почему она показала гораздо лучший результат? Во-первых, GPT-3.5 не предназначена казаться человеком. ChatGPT с этой моделью запрограммирован давать ответы очень формально, не высказывая мнение и его отстаивая.
Учитывая, что людям удавалось сойти за таковых лишь в 63% случаев, возможно, несправедливо быть слишком строгими к "человечности" моделей. В конце концов, тест Тьюринга проверяет не гуманность, а способность ввести человека в заблуждение.
Мы всё ещё на очень ранней стадии развития больших языковых моделей. Кто знает, чего ждать через 5 или даже 10 лет. Возможно, к тому времени в игры будут интегрировать ИИ для создания виртуальных NPC, придания сюжетам сложности и разветвления или предоставления множества выборов.