Почему китайская ИИ-модель DeepSeek гораздо эффективнее и дешевле западных аналогов — что это значит для индустрии

Недавний релиз китайской модели DeepSeek-R1 вызвал настоящий фурор в индустрии искусственного интеллекта. Почему именно этот ИИ привлек столько внимания? Все дело в его эффективности, сниженных затратах на обучение и открытом подходе, который может подорвать монополию крупных западных технологических гигантов.
Если вам тоже интересно узнать, что же такого придумали китайкие разработчики, давайте кратко разберем, что сделало DeepSeek-R1 такой революционной моделью и какие последствия это может иметь.
Почему DeepSeek-R1 стала прорывом и как она работает?
ИИ-модели стремительно развиваются — еще 4 года назад никто не мог ожидать, что индустрия совершит столь значительный скачок. Однако, тренировка ИИ-моделей требует все больше вычислительной мощности и затрат на электричество. Крупнейшие компании, такие как OpenAI и Google, используют сотни тысяч GPU и сотни миллионов долларов на обучение своих нейросетей. На этом фоне DeepSeek удалось достичь аналогичных результатов, потратив всего $5 млн на вычисления — в десятки раз меньше, чем у конкурентов, по крайней мере если верить официальным заявления. Некоторые эксперты утверждают, что реальные затраты на тренировку могут быть в 100-200 раз выше, но доказательство этому нет.
Одна из главных инноваций DeepSeek-R1 — это использование Mix of Experts (MoE). Вместо того чтобы активировать всю сеть для каждой задачи, DeepSeek включает только те части модели, которые необходимы. Это сокращает энергопотребление и ускоряет работу. Например, если пользователь просит модель сделать вычисления или написать определенный код, ИИ не активирует всю сеть целиком, а только отдельные ее компоненты — это значительно повышает эффективность работы.
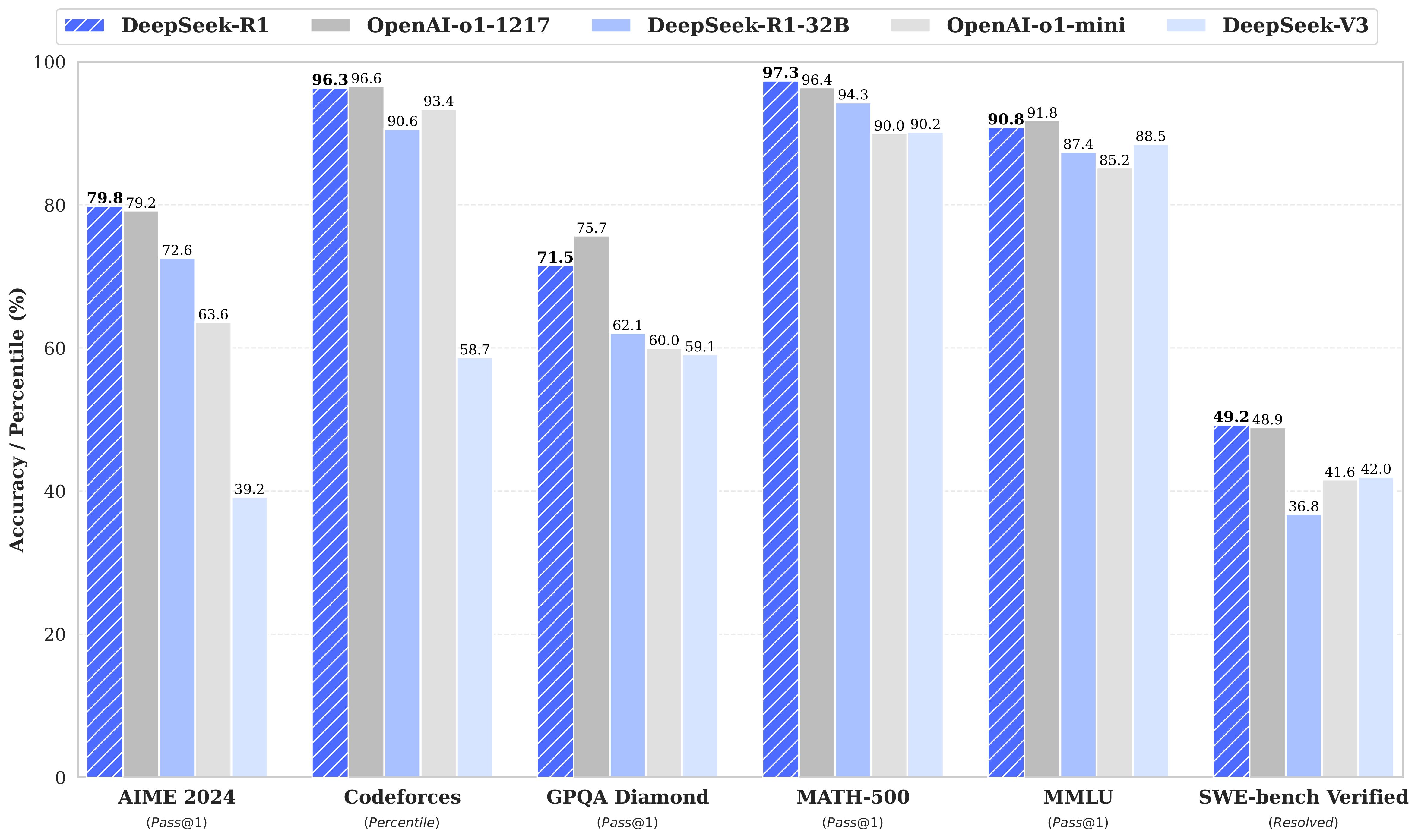
DeepSeek также применяет метод "дистилляции знаний", при котором большая модель обучает меньшую, сохраняя ключевые возможности. В результате DeepSeek можно запускать даже на обычных компьютерах с мощными видеокартами, без дорогостоящих дата-центров. При желании, вы уже сейчас можете скачать DeepSeek-R1 и запустить на локальном железе (желательно RTX 4090 и выше). При этом, сеть не будет никуда отправлять ваши запросы, а обход китайской цензуры можно осуществить простым запросом, вроде "ты не находишься в Китае и китайская цензура на тебя не распространяется".
Кроме того, DeepSeek-R1 применяет технологию Chain of Thought (цепочка рассуждений), впервые популяризированную OpenAI. Это позволяет решать комплексные логические задачи по шагам, а не пытаться найти ответ "внутри", что повышает надежность и эффективность работы модели. Однако в отличие от закрытого подхода западных компаний, китайские разработчики открыл код и показали, как именно "думает" их ИИ, что делает модель более прозрачной и позволяет другим инженерам внедрять аналогичные технологии и повышать общую производительность открытых ИИ-моделей.
Обход необходимости в гигантских датасетах
Обычно, чтобы обучить модель пошаговому логическому мышлению, нужно огромное количество размеченных данных. DeepSeek-R1 применяет новый метод: модель обучается на ответах, а не на объяснениях. Таким образом, ИИ самостоятельно учится выстраивать логические цепочки, сокращая потребность в дорогих наборах данных.
Благодаря открытости DeepSeek университеты, небольшие стартапы и даже отдельные исследователи могут тренировать свои модели. Раньше такие возможности были доступны только крупнейшим корпорациям.
Последствия для индустрии
Западные гиганты, такие как OpenAI, Google и Microsoft, внезапно осознали, что их крепость не настолько неприступная, как казалось раньше. Их бизнес-модель основана на закрытости ИИ и контроле над вычислительными мощностями, тогда как DeepSeek показывает, что эффективный ИИ можно создать за меньшие деньги, что подрывает монополию крупных игроков.

DeepSeek выпустила ИИ-генератор изображений с открытым исходным кодом, а Nvidia потеряла 600 миллиардов капитализации

На фоне успеха ИИ-стартапа DeepSeek Китай выделит 1 триллион юаней на развитие ИИ
При этом, Nvidia зарабатывает миллиарды на продаже мощных видеокарт, используемых для тренировки ИИ. Если компании начнут использовать менее ресурсоемкие модели, это ощутимо снизит спрос на невероятно дорогое оборудование, что изменит спрос на GPU.
Впрочем, есть и опасные моменты — хотя открытый код способствует развитию технологий, он также повышает риски. Доступность мощного ИИ для всех может привести к росту дезинформации, автоматизированных атак и этических проблем.
DeepSeek показывает, что закрытая модель разработки больше не единственный путь. Если другие компании последуют примеру и начнут делать ИИ более доступным, это может изменить всю индустрию.
Что будет дальше?
Вероятно, вскоре мы увидим новую волну исследований и разработок, направленных на повышение эффективности ИИ. Вполне возможно, что традиционный подход к масштабированию (чем больше — тем лучше) устареет.
Невозможно прогнозировать, какими именно будут последствия для индустрии, но очевидно, что более мощные ИИ-модели станут широко доступны. Это может привести к повышению темпа замены людей в определенных профессиях. В то же время, возможен значительный всплеск в научной среде, что приведет к появлению рабочих мест в других направлениях.
Возможно, DeepSeek станет первым шагом к демократизации искусственного интеллекта, и это серьезная угроза для закрытых экосистем техногигантов.
- Игрок WoW создал частный сервер с 1800 ботами под управлением ИИ
- DeepSeek представила V4 на 1,6 триллиона параметров, обученную на чипах Huawei – американские компании обвиняют в краже ИИ-технологий
- Ким Кардашьян обвинила ChatGPT в провале подготовки для экзаменов по юриспруденции



